Torch | How to use WeightedRandomSampler in PyTorch
Data imbalance is one of the biggest challanges in a classification task. It can lead to biased models that struggle to perform well on the underrepresented classes. A powerful tool to address this issue is WeightedRandomSampler in PyTorch, which allows us to adjust the sampling probabilities of each class based on their representation in the dataset. I’m tring to understand how WeightedRandomSampler works with a simple dataset consisting of two classes.
What is WeightedRandomSampler
This sampler is designed to sample elements from dataset according to specified weights. The core idea is straightforward: it increases the likelihood of sampling from the minority class, ensuring that during training, the model encounters a more balanced distribution of classes.
How WeightedRandomSampler works
I generate an imbalanced dataset of 1000 samples, consisting of 90% of class 0 and 10% of class 1 to see how WeightedRandomSampler adjusts the sample distribution.
Without a Sampler
First, let’s see how a dataloader works without a sampler.
Create the imbalanced dataset
1import numpy as np
2import torch
3from torch.utils.data import DataLoader, TensorDataset
4
5# Generate imbalanced dataset
6num_samples = 1000
7class_0 = np.zeros(int(0.9 * num_samples))
8class_1 = np.ones(int(0.1 * num_samples))
9data = np.concatenate([class_0, class_1])
10labels = np.concatenate([class_0, class_1])
11
12# Create TensorDataset contains data, label and index
13tensor_data = TensorDataset(torch.tensor(data, dtype=torch.float32), torch.tensor(labels, dtype=torch.int), torch.tensor(labels, dtype=torch.int))
14
15# Create DataLoader without sampler
16dataloader_no_sampler = DataLoader(tensor_data, batch_size=8, shuffle=True)
Sample distribution without a sampler
Visualize the class distribution in those batches and then summarize the total counts across all batches.
1batch_distributions = []
2for data, labels, idxs in dataloader_no_sampler:
3 # distribution for each batch
4 unique, counts = torch.unique(labels, return_counts=True)
5 batch_distributions.append(dict(zip(unique.numpy(), counts.numpy())))
The first plot contains four subplots, each representing the class distribution for one batch. The imbalance persists across these batches, with class 0 consistently having a higher count than class 1.
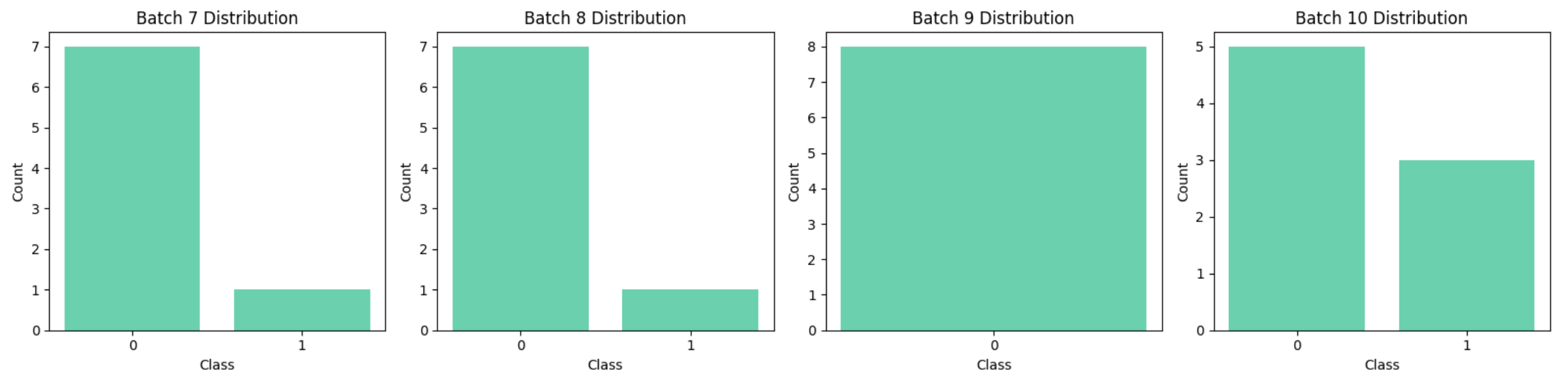
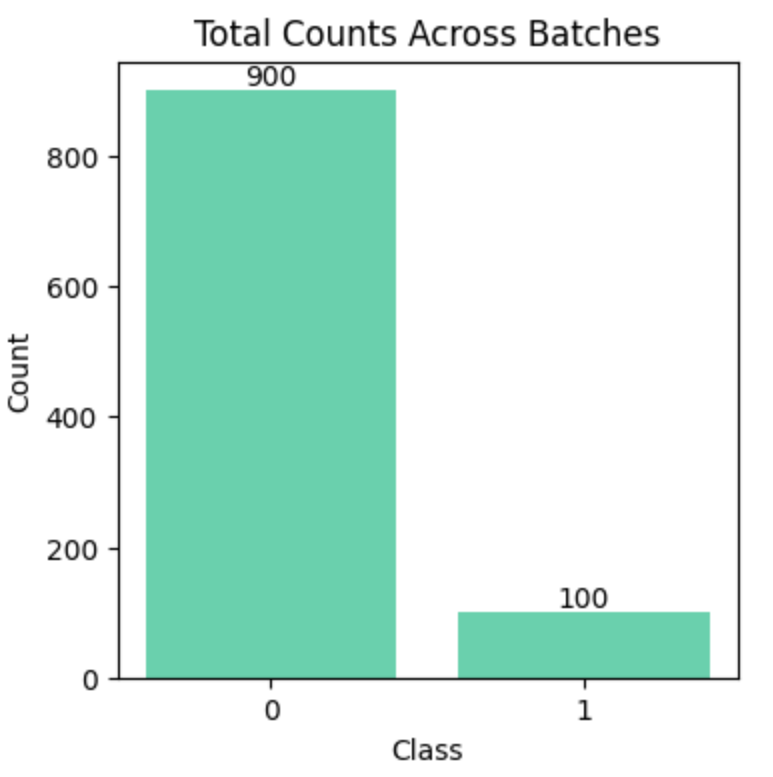
The overall distribution during the training process mirrors the distribution of the imbalanced dataset.
With WeightedRandomSampler
Now let’s create a dataloader with WeightedRandomSampler and see how it help address the data imbalance.
1# Calculate weights inversely proportional to class frequency
2weights = {0: 1.0 / class_counts[0], 1: 1.0 / class_counts[1]}
3sample_weights = [weights[label.item()] for _, label, _ in tensor_data]
4
5# Create WeightedRandomSampler
6sampler = WeightedRandomSampler(weights=sample_weights, num_samples=len(sample_weights), replacement=True)
7
8# Create DataLoader with sampler
9dataloader_with_sampler = DataLoader(tensor_data, sampler=sampler, batch_size=8)
As we can see, the distribution of each batch looks more balanced than before.
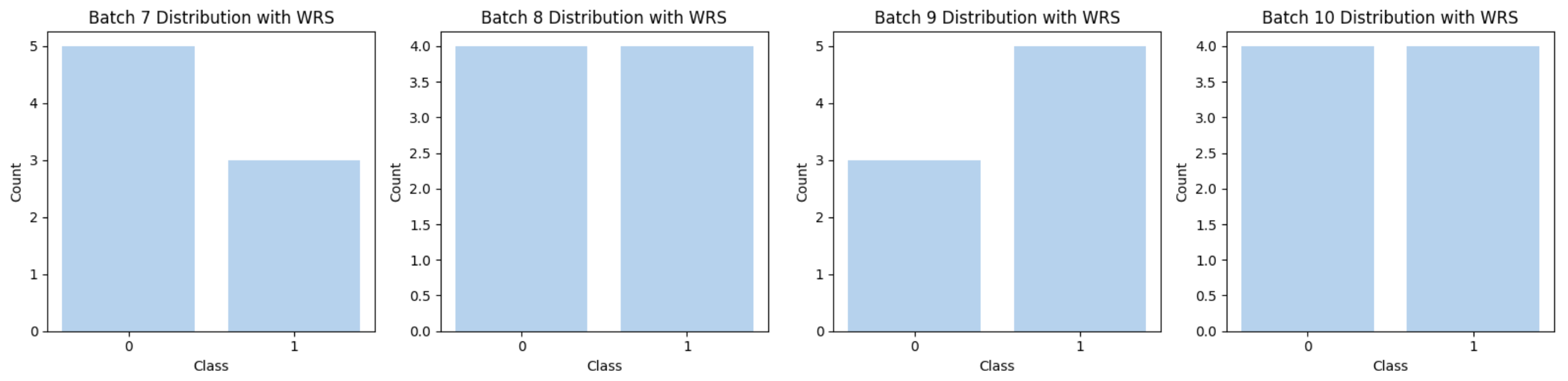
The overall distribution shows the total sample distribution from a single iteration through the dataloader, which still consists of 1,000 samples. However, the counts for the two classes have become more balanced. This typically occurs within one epoch.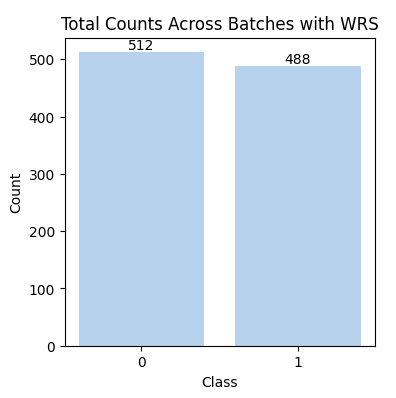
Notice, not all samples from class 0 are selected in this epoch. This is because the sampler adjusts the probability of selecting each class based on their assigned weights. As a result, in each iteration, samples from class 1 may be selected repeatedly and some samples from class 0 won’t be seen. This dynamic sampling ensures a more balanced exposure to both classes during training.
Overall distribution in different epoch
The diagram below shows the overall distribution in a different iteration of the DataLoader I created with WeightedRandomSampler.
This distribution differs from the one shown earlier, as the sampler adjusts the probability of sampling each class,
rather than directly determining which specific samples are selected.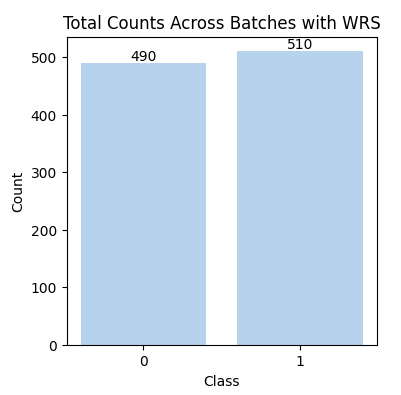
So how many epoch it takes to see all the samples in the dataset?
1num_epoch = 0
2idxs_list = []
3
4while len(set(idxs_list)) < 1000:
5 num_epoch += 1
6 for data, labels, idxs in dataloader_with_sampler:
7 idxs_list.extend(list(idxs.numpy()))
I count the number of epochs required for all samples have been seen during the training. In this case, the number of epochs is 14. In different cases, the number would be different. Here I found a great example that uses Monte Carlo method to observe the distribution of number of epochs for different levels of data imbalance.
What each parameter means
Finally, let’s see what those parameters of WeightedRandomSampler mean.
1sampler = WeightedRandomSampler(
2 weights=sample_weights, # a sequence of weights, not necessary summing up to one
3 num_samples=1000, # number of samples to draw
4 replacement=True, # Whether to sample with replacement
5 generator=torch.manual_seed(42) # Generator used in sampling
6)
weights
weights defines the probability of selecting each sample. The weights do not need to be less than 1. You can have weights like [0.3, 0.6] or just [3, 6] which both can set a higher probability of sampling for the second class.
num_samples
num_samples specifies how many samples should be drawn in total. The num_samples can be larger than the data size, and in that case,
some samples will be repeated during each epoch just as the diagram below shows. The number of class 0 is 1011 which is
larger than its size 900, reflecting the duplicate sampling.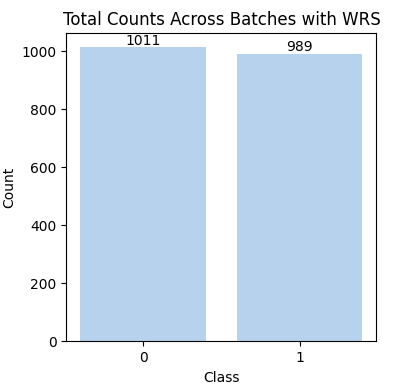
replacement
replacement determines whether to sample with or without replacement. The official doc says:
if True, samples are drawn with replacement. If not, they are drawn without replacement, which means that when a sample index is drawn for a row, it cannot be drawn again for that row.
generator
generator is the generator used in sampling. You can set seed here as shown in the code above.